The discipline of psychology is wringing its hands about its failure to make enough substantial and dependable scientific progress over the last fifty years of effort. First, we blamed our methods: hypothesizing after the results were known, researcher degrees of freedom, p-hacking and the rest. Then, we went after the theories: theories in psychology were so arbitrary, so vague in their relation to anything we could measure, so foundation-less, and so ambiguous, that tests of them were both much too easy, and much too hard. They were much too easy in that they could always be deemed a success. They were much too hard, in that the tests did not generally lead to substantive, cumulative, coherent knowledge. Reforms to the theory-building process were urged (here, here, here). Actually, these critiques were not new: Paul Meehl had made them floridly decades earlier. Writing in the last century, but in a parlance that would have been more at home in the century before, he compared the psychology researcher to: “a potent-but-sterile intellectual rake, who leaves in his merry path a long train of ravished maidens but no viable scientific offspring.”
I read all this with interest, but I remember thinking: “it can’t really be that bad.” I didn’t come across that many obviously terrible theories or terrible tests in my day to day life, or so I felt. I assumed that authors writing about the theory crisis – who obviously had a point in principle – were exaggerating how bad the situation was, for rhetorical effect.
Recently, Joanna Hale and her colleagues have made the important contribution of creating a database of theories in psychology (more specifically, theories that relate to behaviour change). All of the theories are represented in a common formal and graphical way. The database is here, and the paper describing its construction is here.
The database gives us a few useful things about each theory. First, a list of the constructs, the things like self-efficacy or self-esteem or normative motivation or health beliefs or whatever, which constitute its atomic elements. Second, a list of the relations between them (self-efficacy influences normative motivation, self-esteem is part of self-efficacy). And third, combining the first and second, a nice graphical representation, a kind of directed acyclic graph or DAG: which construct, according to the theory, does what to which other construct?
The genius of this database is that our array of theoretical tools (76 different theories, no less) is laid out before us on the bench in utter clarity. I have to say, my immediate reaction is: oh dear, it really is that bad.
Why do I say this? If you look at figure 1 I think you will see why. I chose this theory more or less at random; most are not much different.
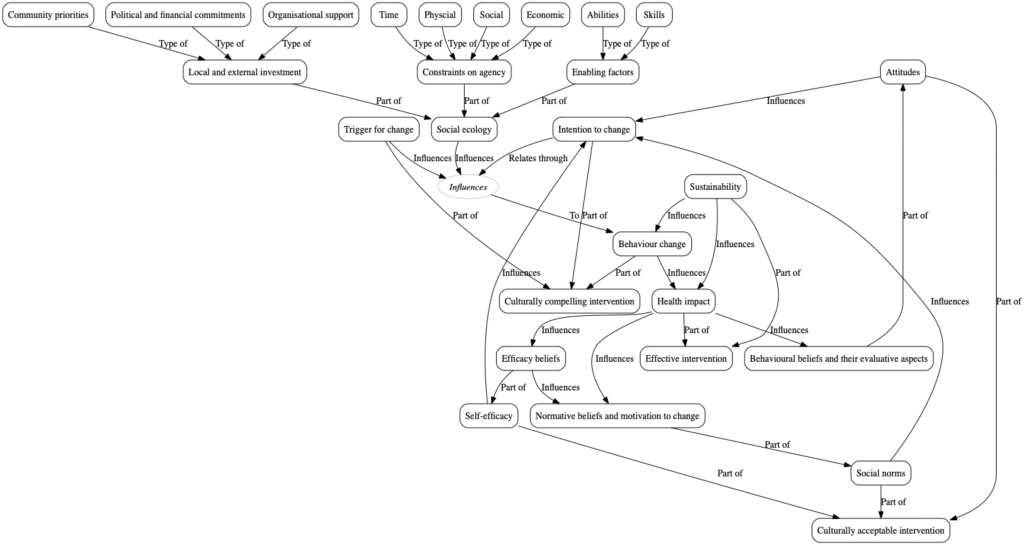
The first and most obvious problem is that the theories contain many links, an average of 31 and a maximum of 89. And that is the direct connections. A connected network with 31 direct links probably has thousands of distinct indirect ways of getting from any upstream construct A to any downstream construct B. Some of these pathways will be mutually suppressive: A has a positive influence on B; but also a positive influence on M which has a negative influence on B. So what should be the empirical covariance of A and B, given that the directions of these associations are specified by the theory but their strengths are not? The theory is consistent with: positive (the direct pathway is dominant); negative (the indirect is dominant); or null (the two pathways cancel each other out). In short, pretty much any pattern of associations between non-adjacent constructs could probably be accommodated in the theory’s big, leaky tent. It’s generally unclear what the systemic effect will be of intervening at any point or in any direction. Moreover, with 31 links and null hypothesis significance testing at p < 0.05, something is definitely going to be associated with something else; there will always be statistically significant results to discuss, though their actual significance will be unclear.
The multiplicity of links is an obvious problem that hides, I think, the much more fundamental one. Psychology’s problem is really one of ontology. In other words, what should be our atoms and molecules? What is in our periodic table? What is the set of entities that we can put into boxes to draw arrows between; that we can fondly imagine entering into causal relationships with other entities, and making people do things in the world?
In the 76 theories, there were 1290 unique constructs. Even allowing for fuzzy matching of names, 80% of those constructs only appeared in a single theory. No construct appeared in all the theories. Only ‘behaviour’ and ‘social’ appeared in more than half the theories, and those are hardly tightly defined. It’s like having 76 theories of chemistry, 80% which name completely unique types of building block (mine’s got phlogiston!), and which contain no type of building block common to them all.
The fact that we lack a stable ontology is really what makes our results so hard to interpret. Let’s take the theory known as ‘the systems model of behaviour change’ (figure 2). The theory distinguishes between (inter alia): the perception of self; the perception of social influence; attitudes; motivation to comply; and health intention. These constructs are all supposed to enter into causal relations with one another.
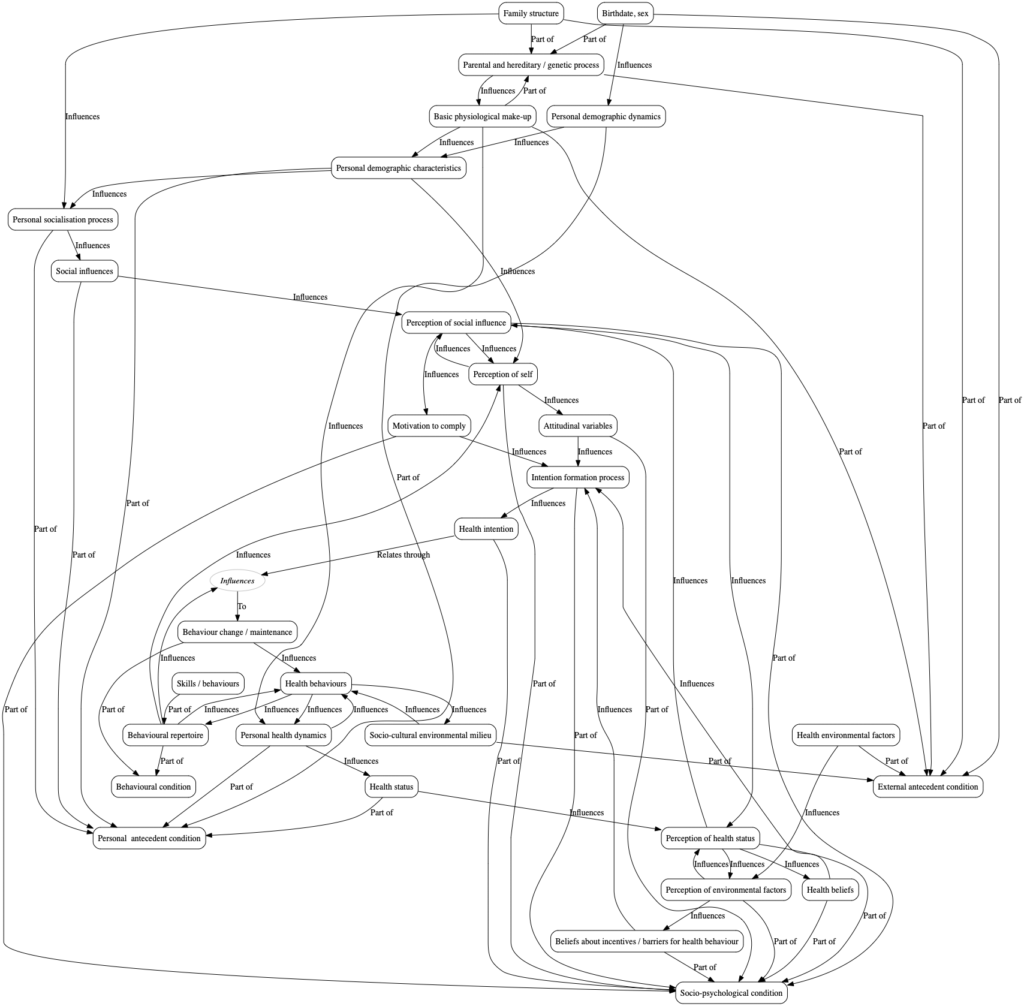
Suppose we measure any two of these, say motivation to comply, and health intention. We find they correlate significantly, at say r = 0.4. At least three things could be going on: (1) the theory is confirmed, and motivation to comply influences health intention; (2) our measurement of at least one of the constructs is impure; one of the questions that we think of as measuring motivation to comply is a really bit reflective of health intention too; thence the correlation is a methodological artifact; (3) motivation to comply and health intention are really the same thing, measured in two noisy ways using different questions; (4) neither motivation to comply or health intention is really a thing, so the correlation is meaningless.
The difficulty, it seems to me, is that the measurement issues cannot be solved whilst the ontological ones are still live (and, probably, vice versa). If we are not sure that X and Y are really two things, then we never know how to interpret the covariance of their measurements. Maybe we haven’t measured them purely; maybe we shouldn’t be measuring them separately; or maybe we have learned something about the structure of the world. None of the various criteria of measurement reliability or validity that circulate in psychology really helps that much. This criticism is most obviously applicable to correlational research, but it affects experimental manipulations too.
The ontological problem is really hard. You might think you can purify your ontology, get it down to bed rock, by eliminating all entities that could be redescribed in more atomic terms. But this approach account cannot be right. Taking it literally, we would need to remove from our ontologies all kinds of very useful things: atoms, elements, organisms, and genes, for example. There would be no science but subatomic physics, and it would take forever to get anywhere. No, there are all kinds of things we want to hang onto even though we know they can be eliminated by redescription.
The criterion for hanging on to an ontological category has to be much looser. Something like that: it reliably shows up for different observers; it is an aspect of a stable level of physical or biological organisation; and it proves itself useful and generative of understanding. Though this is far from clear cut, most of psychology’s ontological cabinet probably does not comply. In fact, who knows where the 1290 constructs in the database come from? Probably a combination of ordinary language, folk psychology, loose analogies, academic carpet-bagging, and random tradition. That’s really our problem.
There is no simple answer to this difficulty. The much-advocated ‘doing more formal modelling’ is not a solution if the entities whose relations are being formally modelled are flaky. Some ontologies are better than others. Generally the better ones (i.e. more stable, and leading to clearer and more accurate predictions) are more rooted in either biology (that is, either neuroscience or evolutionary biology), or in computational frameworks that have proved themselves predictive in a detailed way on lower-level problems (I am thinking of Bayesian models of cognition and their social applications, as discussed here). But, for many parts of ‘whole-person’ psychology, scientific performance in some coefficient of determination sense is not enough. We also want to maximise intuitive gain. The theoretical terms have to generate some insight, not least in the very people whose behaviour is their subject. Some ontologies probably do more for intuitive gain, others for biological realism, and it is hard to find the middle way.
One thing is for sure: we don’t need any more than our (at least) 1290 constructs. Perhaps there ought to be a global ontological non-proliferation treaty. I imagine a permanent conference, domiciled in St. Kitts or Geneva, where teams quietly work towards voluntary reduction in psychology’s ontological stockpiles. Volunteers?